Table of Contents >> Show >> Hide
- What “Game Boy Supercomputer” Actually Means
- Why AI Researchers Care About Video Game Frames
- Why the Game Boy Is a Sneaky-Good AI Playground
- How You Get to “A Billion Frames Per Second” Without Breaking Physics
- What You Can Study With a Game Boy Environment Cluster
- Why Not Just Use GPUs?
- The Bigger Takeaway: Hardware/Software Co-Design Is Back (Again)
- If You Want to Try the Spirit of This at Home
- Conclusion: Tiny Pixels, Big Research Energy
- Field Notes: The “Experience” of Working Around a Game Boy Supercomputer (500+ Words)
If you ever wanted to make artificial intelligence research feel like a retro-gaming montagecomplete with
pixelated screens, dramatic music, and a suspicious amount of coffeegood news: someone basically did.
The twist is that the “Game Boy supercomputer” isn’t a tower of dusty handhelds duct-taped together like a
cyberpunk arts-and-crafts project. It’s far nerdier (and far faster): a high-throughput cluster that runs
Game Boy environments at absurd speed, so reinforcement learning agents can fail, learn, and fail again
at a rate that would make a human player’s thumbs file a formal complaint.
The big idea is simple: reinforcement learning (RL) lives and dies by experience. If your agent needs millions
(or billions) of frames of gameplay to learn “jump at the right time,” waiting for real-time emulation is like
training for a marathon by strolling to the fridge. So researchers chase one thing relentlessly: faster
environments. And in one famously wild build, that chase ends with a “supercomputer” that can crank out
around a billion frames per second across many parallel Game Boy simulationsturning classic games into a
high-speed treadmill for modern AI research.
What “Game Boy Supercomputer” Actually Means
Let’s clear the air: nobody is asking a 1990s handheld to run giant language models. The “supercomputer” label
is shorthand for a cluster built to do one job extremely wellrun many instances of a Game Boy-like system
in parallel, at very high speed, to generate training data for RL algorithms.
In this approach, the Game Boy is the environment (the world the agent interacts with), and the AI system is
the agent (the brain trying to master the world). The environment needs to be accurate enough to behave like
the real thing, but the agent wants it to run at warp speed so it can iterate faster than your “continue?”
screen after a bad boss fight.
So the “supercomputer” isn’t about raw graphics horsepowerit’s about throughput: producing massive amounts
of gameplay experience quickly, consistently, and in bulk.
Why AI Researchers Care About Video Game Frames
Reinforcement learning is experience-hungry
Many deep RL methods learn by trial and error: take an action, observe what happens, get rewarded (or punished),
update the policy, repeat. That loop can demand staggering volumes of interaction. Even in relatively “simple”
benchmarks, it’s common to see agents trained on millions of frames. For harder gamesespecially those with
delayed rewards or unclear objectivesthe amount of experience needed can explode.
That’s why researchers obsess over environment speed. If you can run simulations faster, you can:
- Test more ideas per week (architecture tweaks, reward shaping, exploration strategies).
- Run more seeds (reducing the “it worked once on my laptop” problem).
- Try curricula (training on easier tasks first, then ramping difficulty).
- Explore transfer learning (reusing knowledge across different games or tasks).
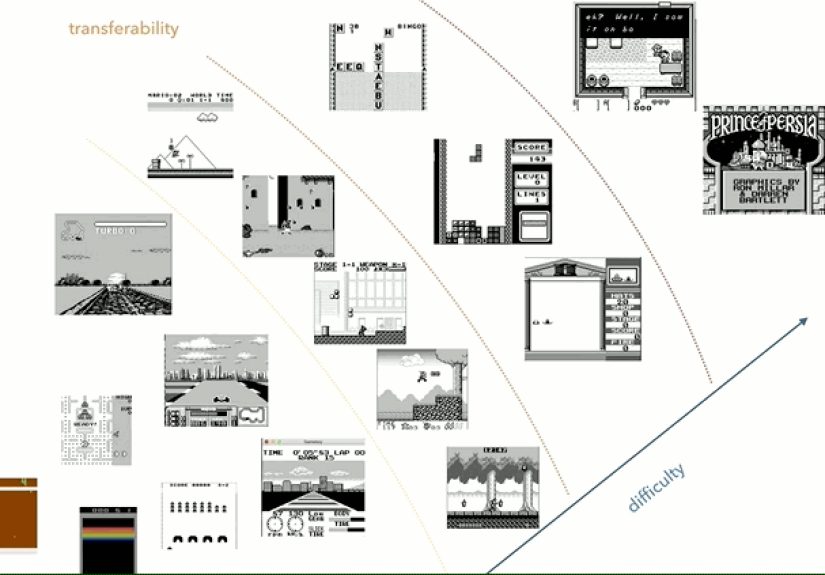
The unsolved headache: transfer and memory
One motivation behind using a large library of Game Boy titles is the long-standing problem of
knowledge transfer: if an agent learns to play one game well, can it use that experience to learn a different
game faster? Humans do this constantly (“this platformer teaches timing,” “this puzzle teaches pattern search”),
but RL agents often learn brittle, game-specific habits.
A fast, diverse, low-cost environment library is perfect for pushing on this question. It lets researchers ask:
does skill in a game with tight timing help in another with similar dynamics? Do agents learn reusable concepts,
or just memorize action sequences?
Why the Game Boy Is a Sneaky-Good AI Playground
The Game Boy hits a rare sweet spot for RL research:
-
Huge variety of games: the platform has a large catalog spanning genres and difficulty, which is handy for
studying generalization instead of one-game heroics. -
Small observations: the classic display is low resolution (160×144) and limited color depth, making it far
cheaper to process than modern 3D games. -
Simple hardware model: compared with later consoles, the Game Boy is easier to emulate accurately and run
at scale. -
Rich RL challenges: many games have delayed rewards, partial observability, and long-horizon planningthings
that expose weaknesses in “pure reflex” agents.
In other words, it’s complex enough to be interesting, but small enough to be fast. Like a tiny gym that still
has squat racks.
How You Get to “A Billion Frames Per Second” Without Breaking Physics
The headline number sounds like sci-fi until you realize the trick: parallelism + specialized hardware.
Instead of one emulator running faster, you run many emulated systems in parallel, each running fast enough to
be useful, and you aggregate the throughput.
Step 1: Build (or use) a Game Boy emulator as a research environment
The foundation is an emulator that can be controlled programmaticallymeaning an RL agent can read observations
(screens, RAM, game state proxies) and send actions (button presses). That turns a retro game into an
experiment-friendly environment, similar in spirit to popular RL toolkits and benchmarks.
If you’re doing this in software, you’ll quickly discover the boring truth of ML engineering:
your agent isn’t always the slow part. Often, the environment becomes the bottleneckespecially if you’re
running thousands of parallel episodes.
Step 2: Move from software emulation to hardware-accelerated emulation (FPGAs)
Here’s where the build gets spicy. Rather than emulating the console purely in software on CPUs or GPUs, the
system uses field-programmable gate arrays (FPGAs)chips that can be configured to implement custom digital
circuits. That makes them a strong fit for workloads where you want lots of small, efficient “cores” running in
parallel and doing predictable low-level computation.
Hardware description languages (like Verilog) let you describe logic that effectively becomes custom hardware
once synthesized onto an FPGA. In this case, that logic behaves like the Game Boy’s internalsso you’re not
“running an emulator” so much as you’re “instantiating many tiny Game Boys in silicon.”
Step 3: Scale outmany chips, many virtual consoles, huge aggregate speed
With the environment implemented on FPGAs, the system can run extremely fast per chip and also run many
instances per chip. Scale that across a large cluster of FPGA boards, and the throughput stacks up.
One widely cited configuration describes thousands of FPGA chips wired together, producing roughly
~1 billion frames per second in aggregate from hundreds of emulated Game Boyswhile only using a single
physical Game Boy for validation testing. That’s an important detail: the “Game Boy supercomputer” is mainly a
supercomputer of Game Boy-like simulations, not a museum display of handhelds.
What You Can Study With a Game Boy Environment Cluster
A setup like this isn’t a party trick; it’s a research instrument. Here are the kinds of questions it’s built
to answer.
1) Transfer learning across games
If you can train agents quickly across many titles, you can run structured experiments on generalization:
train on a set of “source” games, then measure how quickly the agent learns “target” games. You can group games
by mechanics (timing, navigation, resource management) and test whether representations carry over.
2) Memory and long-horizon planning
Games with delayed consequences are brutal for agents that only react to the last few frames. Many Game Boy
titles require remembering what happened minutes ago, planning multi-step strategies, or navigating without
immediate reward signals. That makes them useful for studying memory-augmented models and better exploration.
3) Curriculum design (learning the easy stuff first)
With fast simulation, you can stage learning: start with reactive games, move to platformers, then to complex
titles with sparse rewards. This isn’t just “nice to have”it can be the difference between learning and
flailing forever.
4) Sample efficiency vs. brute force
Speed can tempt researchers into “just throw more frames at it.” But that’s also why a fast cluster is useful:
it helps separate questions of algorithmic efficiency from wall-clock constraints. You can compare methods
fairly by matching environment frames and seeing which agents learn more per unit experiencenot just per hour.
Why Not Just Use GPUs?
GPUs are fantastic for training neural networks, especially when the work is dense, numeric, and highly
parallel in a uniform way (think matrix multiplications). But emulation can be irregular: lots of branching,
small operations, and stateful logic. FPGAs can be attractive when you want:
- Many lightweight cores that do low-level steps efficiently.
- Deterministic timing and predictable performance per instance.
- Energy-efficient throughput for specific workloads.
In practice, modern RL systems often mix approaches: GPUs for learning, CPUs for orchestration, and specialized
hardware (including FPGAs) when environment simulation becomes the limiting factor.
The Bigger Takeaway: Hardware/Software Co-Design Is Back (Again)
AI history has a recurring theme: algorithms make a leap, then hardware chases them, then the next leap comes
from designing the two together. Today’s AI acceleration is usually framed around GPUs and big transformer
training. But reinforcement learning and simulation-heavy research frequently win by a different metric:
how fast you can generate high-quality experience.
That’s why you see parallel ideas across the industry: faster simulators, batched environments, dedicated
acceleration, and toolkits built around standardized agent/environment APIs. The Game Boy “supercomputer” is a
dramatic example of the same instincttake the bottleneck seriously, then obliterate it with engineering.
If You Want to Try the Spirit of This at Home
Most people will not be wiring together four-digit counts of FPGA chips in their garage (and if you do, please
label your cablesfuture you deserves kindness). But you can still capture the core workflow:
- Use standardized RL interfaces so agents can swap environments easily.
- Vectorize environments (run many in parallel) to increase throughput.
- Profile early: find whether training, simulation, preprocessing, or logging is slowing you down.
- Measure transfer explicitly: don’t just ask “did it learn?”ask “did it reuse what it learned?”
The point isn’t to worship the hardware. The point is to build systems that let you run more clean experiments,
faster, with less waiting around for a progress bar to inch forward like it’s roleplaying as a Game Boy text
crawl.
Conclusion: Tiny Pixels, Big Research Energy
A Game Boy supercomputer for AI research sounds like a joke someone made at 2 a.m. during a hackathon. But it
highlights a very real truth: progress in reinforcement learning isn’t only about smarter algorithmsit’s also
about building the machinery that lets you test smarter algorithms at scale.
By combining a wide game library, low-cost observations, and extreme parallel simulation speed, a Game Boy
environment cluster becomes a powerful lab for studying generalization, memory, and transfersome of the hardest
open problems in RL. And it does it with the comedic charm of turning childhood pixels into industrial-grade
research infrastructure.
Field Notes: The “Experience” of Working Around a Game Boy Supercomputer (500+ Words)
Even if you never touch an FPGA cluster, the moment you start building fast RL pipelines around retro-game
environments, you’ll have a very specific set of experiencesequal parts delight, confusion, and “why is this
one sprite ruining my whole experiment?” Here’s what people typically run into when they chase the Game Boy
supercomputer vibe in real projects.
First, there’s the thrill of speed. The initial jump from real-time gameplay to thousands of frames per second
feels like discovering a cheat code that’s somehow legal. Episodes that used to take minutes finish in seconds.
Your training curves update fast enough to make you suspicious. (“This is too smooth. Did I accidentally train
on the evaluation set?”) When throughput is high, you stop treating experiments like precious gems and start
treating them like popcornrun another batch, change one variable, run it again.
Then comes the humbling realization: speed doesn’t automatically mean progress. With fast environments you can
generate oceans of data, but the agent can still learn nonsense. It might discover a loophole (standing still to
avoid negative rewards), overfit to one level layout, or learn a behavior that looks clever until it hits a new
situation and collapses like a folding chair. High throughput doesn’t remove the need for good reward design,
robust evaluation, or careful generalization testsit just makes your mistakes happen faster. (Which, to be
fair, is still a productivity win.)
You’ll also experience the tyranny of tooling. To get meaningful research outcomes, you end up building a
small universe of support systems: deterministic seeding, synchronized resets, fast frame capture, action
repeat logic, and logging that doesn’t murder performance. At some point you will say, out loud, “I am no longer
training an agent; I am running a small airline,” because you’re scheduling thousands of parallel rollouts and
dealing with the equivalent of gate delays.
If you push toward hardware acceleration, the experience becomes a blend of software and hardware debugging.
You learn that accuracy mattersan emulator that’s “mostly right” can still poison results. A subtle timing bug,
an off-by-one in input handling, or a quirky rendering mismatch might not crash anything, but it can shift agent
behavior in ways that make comparisons meaningless. The weirdest part is that your AI may adapt to the bug. It
will happily learn the laws of your broken universe and become the champion of glitches. Congratulations: you
invented a new sport.
Another surprisingly common experience is rethinking what “difficulty” means. Some games that are hard for humans
are easy for agents because they’re repetitive or highly reactive. Others that feel simple become brutal
because reward is sparse or delayed. You start sorting tasks not by nostalgia, but by properties like reward
density, partial observability, and whether the game communicates consequences quickly. You also develop a deep
appreciation for any game that puts a score on screen at all times. Sparse reward can feel like training in a
sensory deprivation tank.
Finally, there’s the most valuable experience: transfer experiments teach humility. You expect skills to carry over,
but often they don’t. Or they transfer in weird ways. Your agent might learn timing from one platformer and show
mild improvement in another, but completely fail in a puzzle game that shares the same input space. When you do
see transfer, it feels like spotting a rare animal in the wild: exciting, fragile, and easy to scare away with
one small change. That’s exactly why a fast Game Boy environment cluster mattersbecause it lets you run enough
controlled trials to distinguish real transfer from coincidence.
In the end, the “Game Boy supercomputer” experience is less about retro hardware romance and more about
building a research engine: fast environments, clean measurements, and lots of parallel attempts to answer the
question that still haunts RLcan agents learn reusable knowledge, or are they just speedrunning one game at a
time?




